

Artificial intelligence (AI) is rapidly transforming the world, and Large Language Models (LLMs) are at the forefront of this revolution. These sophisticated AI systems, trained on massive datasets of text and code, can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
They have the potential to revolutionize various industries, from customer service and education to healthcare and scientific research. I
A world where AI assistants can provide personalized tutoring, automate complex tasks, and even accelerate scientific discovery. This article delves into the capabilities of several leading LLMs, including QwenLM, DeepSeek, Kimi 1.5, Claude, ChatGPT, and Gemini Pro, providing a comparative analysis of their features, strengths, and weaknesses.
Let’s start with QwenLM…
1. QwenLM 2.5 max
Developed by Alibaba Cloud, QwenLM is a family of LLMs designed to tackle various natural language processing tasks. QwenLM boasts impressive capabilities, including:
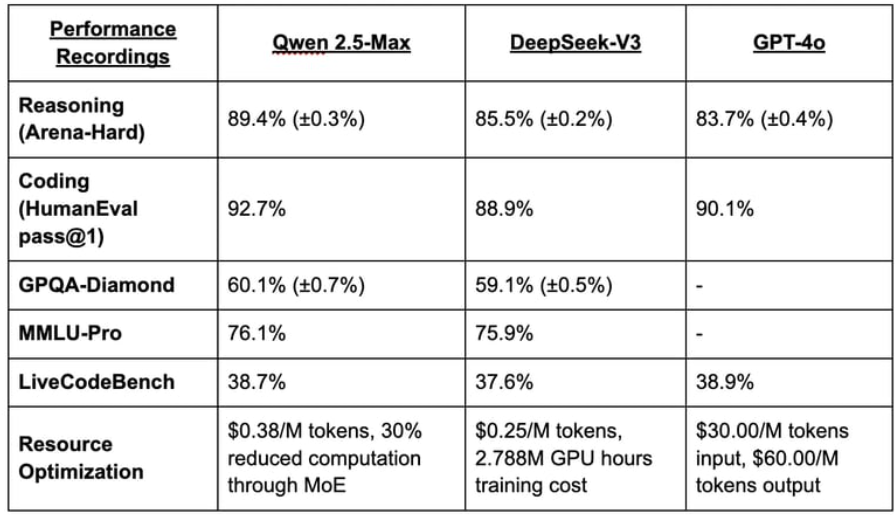
Trained on 20 trillion tokens, Qwen2.5-Max has a vast knowledge base and excels in general AI tasks.
It uses Mixture-of-Experts (MoE) Architecture which allows QwenLM to activate only the necessary parameters for a given task, enhancing efficiency and scalability. This is achieved by dividing the model into specialized sub-networks (“experts”) that handle different types of input. For example, if you ask a complex question about physics, only the experts in physics respond, while the rest of the model remains inactive.
QwenLM demonstrates competitive results across 29 languages, including Python, C++, and JavaScript. This multilingual capability is achieved through a specialized tokenizer that efficiently encodes information from different languages.
QwenLM has consistently focused on extending context length. Qwen2.5-Turbo pushes this to an unprecedented 1 million tokens, employing advanced strategies like Dual Chunk Attention (DCA), Sparse Attention Mechanisms, and Dynamic Sparse Attention with Context Memory. This allows it to process extensive text inputs, making it suitable for tasks like summarizing lengthy documents or engaging in complex dialogues.
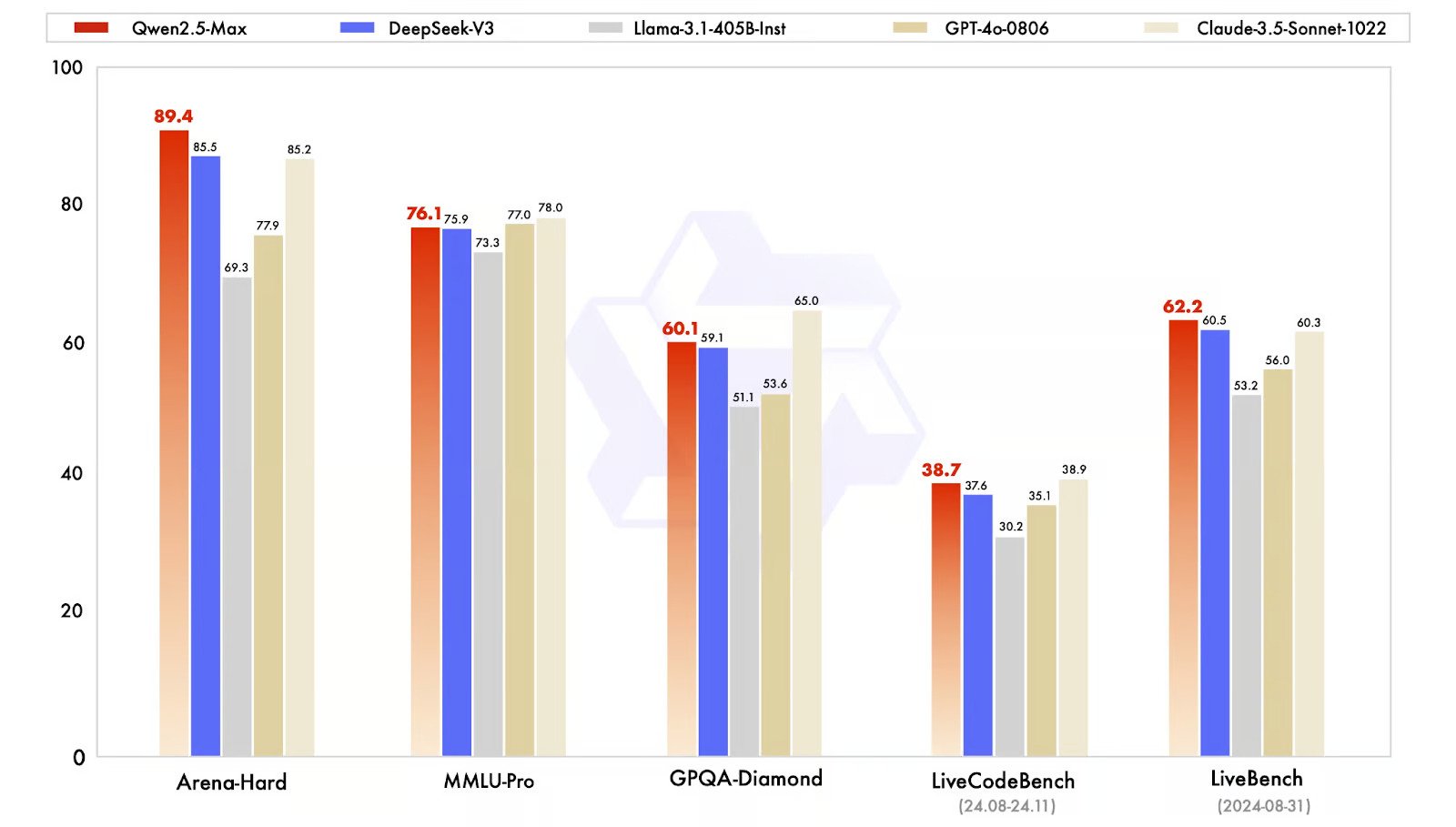
QwenLM has been rigorously evaluated against other leading AI models, showcasing its competitive performance:
- Arena-Hard: Qwen2.5-Max scores 89.4, surpassing DeepSeek V3 (85.5) and Claude 3.5 Sonnet (85.2).
- LiveBench: Qwen2.5-Max leads with a score of 62.2, outperforming DeepSeek V3 (60.5) and Claude 3.5 Sonnet.
- MMLU-Pro: Qwen2.5-Max achieves a score of 76.1, demonstrating strong knowledge and reasoning capabilities.
- C-Eval: Qwen2.5-Max scores 92.2, outperforming DeepSeek V3 and Llama 3.1-405B [39].
- HumanEval: Qwen2.5-Max scores 73.2, slightly ahead of DeepSeek V3 and significantly ahead of Llama 3.1-405B [39].
- GSM8K: Qwen2.5-Max achieves 94.5, well ahead of DeepSeek V3 (89.3) and Llama 3.1-405B (89.0) [39].
While QwenLM may not be explicitly designed as a reasoning model like DeepSeek R1 or OpenAI’s o1, it still demonstrates strong performance in reasoning tasks, as evidenced by its performance on benchmarks like MMLU-Pro and LiveBench.
QwenLM is available through Alibaba Cloud services and can be accessed via Qwen Chat. Users can also access it through ModelScope and Hugging Face.
2. DeepSeek
DeepSeek, a Chinese AI startup, has made waves with its open-source LLMs that rival the performance of established players. DeepSeek’s key features include:
DeepSeek-R1 was reportedly trained on a budget of $6 million, significantly lower than the cost of training comparable models. This challenges the assumption that massive resources are necessary for developing high-performing LLMs. This cost-effectiveness is achieved through several innovative techniques, including:
It optimized the use of NVIDIA H800 GPUs, which have lower chip-to-chip bandwidth compared to newer models, by focusing on low-level code optimizations to maximize memory efficiency .
This technique ensures that only the most relevant parts of the model are activated and updated during training, reducing computational overhead.
This method compresses key-value pairs in the model’s attention mechanism, reducing memory requirements without sacrificing performance.
DeepSeek uses reinforcement learning to improve model learning efficiency by focusing on tasks with clear, verifiable answers, such as math and coding problems.
DeepSeek-R1 excels in reasoning tasks, particularly in mathematics and coding. This is achieved through a multi-stage training process that combines supervised fine-tuning with reinforcement learning.
DeepSeek’s open-source approach fosters community-driven development and customization. This allows developers and researchers to explore, modify, and deploy the model within certain technical limits.
DeepSeek-V3 can handle both text and images, enabling it to perform tasks like image captioning and visual question answering.
It can be run on local machines, thanks to its small footprint, increasing accessibility and allowing for offline use.
DeepSeek utilizes MLA to improve inference efficiency. This technique involves low-rank joint compression of attention keys and values, reducing computational overhead without compromising performance.
DeepSeek-R1 has demonstrated impressive performance on various benchmarks:
- AIME 2024: DeepSeek-R1 scores 79.8%, slightly ahead of OpenAI o1-1217 at 79.2%.
- MATH-500: DeepSeek-R1 leads with a score of 97.3%, surpassing OpenAI o1-1217 at 96.4%.
- Codeforces: DeepSeek-R1 achieves a competitive 96.3%, closely trailing OpenAI o1-1217 at 96.6%.
- SWE-bench Verified: DeepSeek-R1 scores 49.2%, slightly ahead of OpenAI o1-1217 at 48.9%.
DeepSeek-V3 boasts 671 billion parameters and was trained on a massive dataset of 14.8 trillion tokens. DeepSeek’s hosted model costs $0.55 per million input tokens and $2.19 per million output tokens, making it significantly cheaper than OpenAI’s o1 model.
World’s First Deep Seek R1 AI App Includes All the 150+ Premium AI Apps Such as Deep Seek, ChatGPT, Meta Llama 3.1, Gemini, Midjourney, Copilot, Dall-E, Leonardo, Synthesia, Pictory AI, Jasper AI, Deep Motion, Canva AI and More in 1 Dashboard for Lifetime Without Any Monthly Fee!
Here are the Unique Features of DeepSeak:-
- Pay and use all the premium models in the world for Lifetime
- No need to pay any API cost or monthly fee
- Get Instant Access to 150+ Premium Ai models in 1 dashboard.
- Generate Response, Lifelike voices, Stunning 4k HD images, 8k captivating, and more.
- Unlimited usage with no restrictions.
- Replace all your expensive tools and services.
- Say goodbye to monthly fees forever.
- Includes a commercial license—generate and sell unlimited assets to clients.
- Beginner-friendly with an intuitive, easy-to-use dashboard.
- No downloads, installations, or customizations—get started instantly.
- Backed by a 30-day iron-clad money-back guarantee.
- FULL Commercial License Included – sell Lead generation services to clients
3. Kimi 1.5
Developed by Moonshot AI, Kimi 1.5 is a multimodal LLM that excels in STEM, coding, and general reasoning. Its key features include:
Kimi 1.5 leverages RL to improve its reasoning capabilities, allowing it to learn from rewards and explore different solutions. This is achieved through a streamlined RL framework that avoids complex techniques like Monte Carlo tree search or value functions.
With a 128k-token context window, Kimi 1.5 can handle complex reasoning tasks and long texts efficiently. This is achieved through partial rollouts, where the model reuses chunks of previous trajectories to avoid regenerating entire responses, improving training efficiency.
Kimi 1.5 can process and reason across text, code, and visual data, enabling it to solve problems that require understanding different modalities. This is achieved through joint training on text and vision data, allowing the model to analyze diagrams, solve geometry problems, and debug code while connecting dots across modalities.
Kimi 1.5 employs the Long2Short method, which bridges efficiency and performance by distilling long-chain reasoning into shorter responses. This involves techniques like model merging, shortest rejection sampling, and DPO optimization.
It can handle 50+ files at once and supports web searches across 100+ sites, showcasing its versatility and research capabilities.
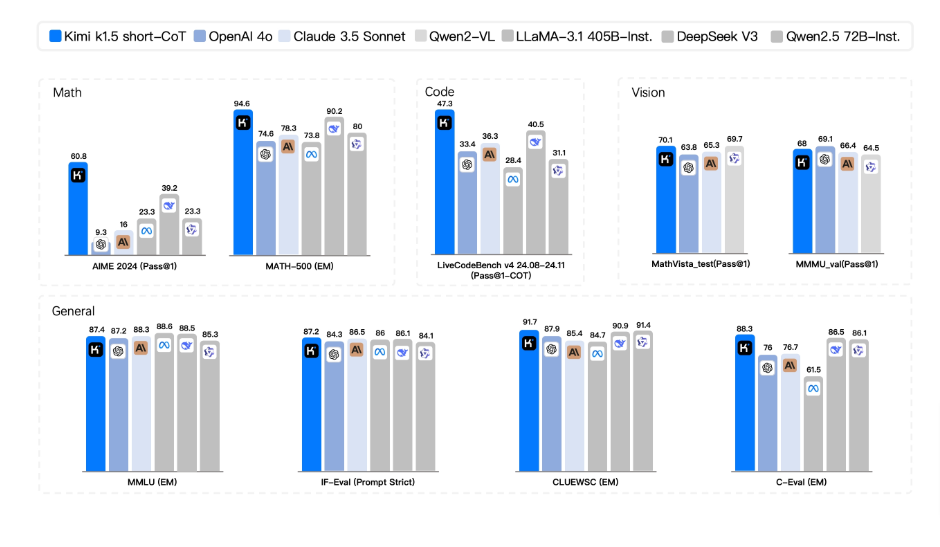
Kimi 1.5 has achieved remarkable results on various benchmarks:
- AIME 2024: Kimi 1.5 achieves a perfect score of 77.5, surpassing OpenAI o1 (74.4) and OpenAI o1 mini (63.6).
- MATH-500: Kimi 1.5 scores 96.2, outperforming OpenAI o1 with a 94.8 score.
- Codeforces: Kimi 1.5 achieves a score of 94, matching OpenAI o1 and exceeding o1-mini and QwQ 72B preview.
- MathVista: Kimi 1.5 achieves 74.9% accuracy, surpassing OpenAI o1 (71%) and other models.
4. Anthropic’s Claude
Developed by Anthropic, Claude is an LLM that prioritizes safety and alignment with human values. Claude’s key features include:
It is trained using Constitutional AI, a technique that aims to align AI systems with human values and prevent harmful outputs. This approach involves providing the AI with a set of principles and guidelines to ensure its responses are ethical and harmless. This is achieved through a two-phase process: supervised learning and reinforcement learning from AI feedback (RLAIF).
Claude has demonstrated strong performance in tasks that require reasoning, common sense, and following instructions. This makes it suitable for applications that demand logical thinking and understanding of everyday concepts.
Anthropic’s focus on safety has resulted in Claude exhibiting lower levels of toxicity and bias compared to some other LLMs. This is crucial for building AI systems that are fair, unbiased, and avoid generating harmful or discriminatory content.
Claude can handle different creative text formats, like poems, code, scripts, musical pieces, email, letters, etc., making it a versatile tool for various writing tasks.
It can summarize factual topics, providing concise and informative overviews of various subjects. Also can answer your questions in an informative way, even if they are open ended, challenging, or strange.
5. ChatGPT
Developed by OpenAI, ChatGPT is one of the most widely known LLMs, popular for its conversational abilities and user-friendly interface. ChatGPT’s key features include:
ChatGPT excels at generating human-like text, making it suitable for tasks like writing stories, poems, and articles. This is achieved through a transformer-based architecture that allows the model to understand and generate text by processing relationships between words in a sequence.
ChatGPT can maintain context over long conversations, enabling more natural and engaging interactions. This is achieved through a memory bank that automatically picks up on details and preferences shared in the chat to tailor its responses.
ChatGPT can process and generate responses that incorporate text and images. This is achieved through the GPT Vision model, which allows ChatGPT to interpret images and use the information as context for other prompts.
It can access the internet for up-to-date information through Browse with Bing. This allows the model to answer questions and complete tasks that require knowledge beyond its static training data.
ChatGPT can interact with data documents (Excel, CSV, JSON) to answer quantitative questions, fix data errors, and produce visualizations.
It allows users to interact with it by speaking using the ChatGPT mobile app or have it read answers aloud in the web version.
ChatGPT has set a high standard for conversational AI, with its ability to engage in natural and coherent conversations. However, it faces challenges related to potential biases in its training data and limitations in its knowledge base, which can sometimes lead to inaccurate or incomplete information.
6. Gemini Pro:
Developed by Google DeepMind, Gemini Pro is a multimodal LLM designed to excel in various tasks, including reasoning, code generation, and long-document analysis. Its key features include:
It can handle text, images, audio, and video inputs, making it suitable for a wide range of applications. This is achieved through a unified internal representation that allows the model to process diverse data types seamlessly.
With a context window of up to 1 million tokens, extendable to 2 million tokens, Gemini Pro can process extensive amounts of information . This allows it to handle tasks involving long documents, extensive codebases, or lengthy audio and video files.
It uses Mixture-of-Experts (MoE) Architecture allows Gemini Pro to activate only the necessary parameters for a given task, enhancing efficiency and performance. This is achieved by dividing the model into specialized sub-networks (“experts”) that handle different types of input, similar to QwenLM’s MoE architecture.
Gemini Pro excels in various text-based tasks, including content creation, summarization, translation, and question answering. Users can create customized versions of Gemini Pro, known as Gems, tailored to specific tasks and preferences.
Gemini Pro can produce structured output from unstructured data and supports enhanced function calling capabilities. This makes it easier to integrate with other systems and extract useful information from various data formats.
It integrates with Google Cloud services, including Vertex AI, and tools like Google Workspace 15. This allows for easy deployment and management of AI-driven applications across different platforms.
The model includes automatic safety features, adjustable by developers, ensuring that outputs are safe and appropriate for various use cases.
Gemini Pro has demonstrated impressive performance on various benchmarks, particularly in tasks involving long-context understanding and multimodal reasoning. It has achieved near-perfect “needle” recall of up to 1 million tokens in all modalities, including text, video, and audio.
Limitations of LLMs
While LLMs have demonstrated remarkable capabilities, it’s important to acknowledge their limitations. These include:
- Potential Biases: LLMs are trained on massive datasets of text and code, which can reflect societal biases. This can lead to AI systems generating outputs that perpetuate harmful stereotypes or discriminatory views.
- Ethical Concerns: The ability of LLMs to generate human-like text raises ethical concerns about their potential misuse for malicious purposes, such as creating fake news or impersonating individuals.
- Factual Accuracy: LLMs can sometimes generate incorrect or misleading information, often referred to as “hallucinations.” This highlights the need for careful evaluation and verification of LLM outputs, especially when dealing with factual information.
World’s First Deep Seek R1 AI App Includes All the 150+ Premium AI Apps Such as Deep Seek, ChatGPT, Meta Llama 3.1, Gemini, Midjourney, Copilot, Dall-E, Leonardo, Synthesia, Pictory AI, Jasper AI, Deep Motion, Canva AI and More in 1 Dashboard for Lifetime Without Any Monthly Fee!
Here are the Unique Features of DeepSeak:-
- Pay and use all the premium models in the world for Lifetime
- No need to pay any API cost or monthly fee
- Get Instant Access to 150+ Premium Ai models in 1 dashboard.
- Generate Response, Lifelike voices, Stunning 4k HD images, 8k captivating, and more.
- Unlimited usage with no restrictions.
- Replace all your expensive tools and services.
- Say goodbye to monthly fees forever.
- Includes a commercial license—generate and sell unlimited assets to clients.
- Beginner-friendly with an intuitive, easy-to-use dashboard.
- No downloads, installations, or customizations—get started instantly.
- Backed by a 30-day iron-clad money-back guarantee.
- FULL Commercial License Included – sell Lead generation services to clients
The Future of LLMs
The field of LLMs is constantly evolving, with ongoing research and development pushing the boundaries of AI capabilities. Researchers are actively working on enhancing the reasoning and problem-solving abilities of LLMs, enabling them to tackle more complex tasks and provide more accurate solutions.
Future LLMs are likely to have a deeper understanding of different modalities, such as text, images, audio, and video, allowing them to interact with the world in a more human-like way.
As LLMs become more powerful, ethical considerations will play a crucial role in their development and deployment. This includes ensuring fairness, transparency, and accountability in AI systems.
Conclusion: A Quick Recap
The LLMs discussed in this article represent significant advancements in AI, each with its own strengths and weaknesses. QwenLM demonstrates strong general AI capabilities, multilingual proficiency, and a focus on long context handling.
DeepSeek disrupts the field with its open-source approach, cost-effectiveness, and advanced reasoning capabilities. Kimi 1.5 excels in multimodal reasoning, complex problem-solving, and efficient handling of long contexts.
Claude prioritizes safety and alignment with human values, aiming to mitigate potential risks associated with LLMs.
ChatGPT remains a popular choice for its conversational abilities and user-friendly interface.
Gemini Pro stands out with its multimodal processing, scalable context window, and advanced text generation capabilities.
As AI continues to evolve, these LLMs will likely play a crucial role in shaping the future of technology and human-computer interaction. Their development and refinement will further enhance their capabilities, leading to new applications and possibilities across various domains. However, it’s essential to address the ethical considerations and potential risks associated with LLMs to ensure their responsible development and deployment.




